
2023年度总结
前言时间过得可真快,眨眼间一年时光便转瞬即逝。
以前从未尝试过写关于自己的年度总结,每至年末总是习惯于打开各大App查看现成的年度报告,每次看到那日积月累起来的数据量总是会惊叹一句:原来我看过这么多视频/电影/文章……
但这些数据好像并不能很好地体现出我的个人意志,于是也就萌生了自己写篇洋洋洒洒的个人年度总结的冲动啦,仪式感还是要有的!
娱乐阅读今年共阅读了41本书,翻过了10933页的书籍,在豆瓣上写了短评82篇共1554字。
在小学乃至初中时都对阅读不太感兴趣,特别是初中12本名著看过的可谓屈指可数,主打的就是一个越是强迫要看的越是不想看。
到中考结束后那段暑假后态度发生了转变,因宅家无所事事开始重新捧起在书柜上蒙尘多年的《巴黎圣母院》,开始迷上了小说,后来慢慢把家里有的从前没读过的书都读了一遍,不够满足继续网购+泡书店不断读书,也接触了反乌托邦文学、法国文学、存在主义文学和大量的历史类书籍,由衷地体会到了阅读所带来的满足感和乐趣。
今年最喜欢的书当属奥威尔的《一九八四》,惊叹于奥威尔的想象力、洞察力与预言能力,看完之后令人不寒而栗,特别是第三部对温斯顿被折磨后的外貌及心理描写都让 ...
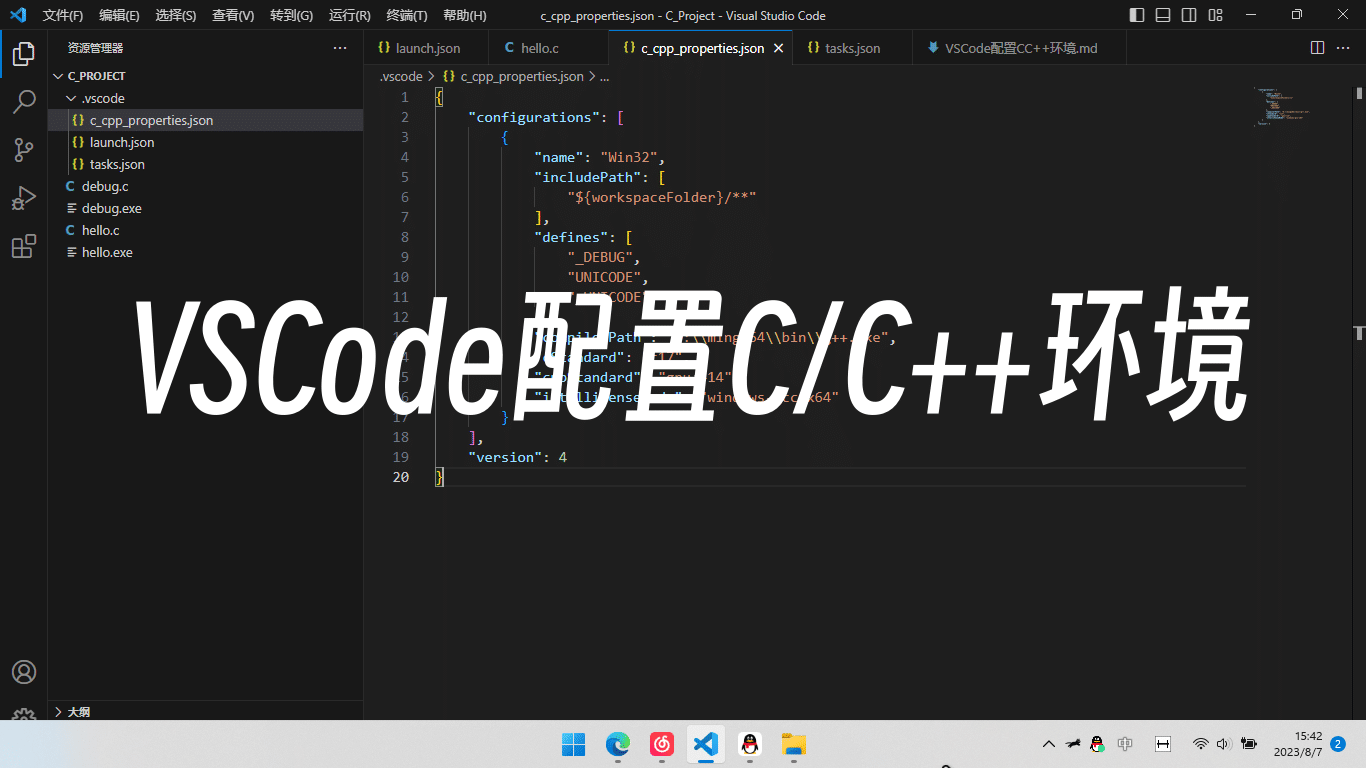
VSCode配置C/C++环境
安装VSCode本文不对安装VSCode展开阐述,请自行前往VSCode下载安装。
安装MinGW编译器前往MinGW下载编译器。
将页面拉至下方,参考下表选择对应版本下载并解压即可。笔者选择为x86_64-win32-seh
名称
说明
Version
最新版本
Architecture
x86_64 (64位) or i686 (32位)
Threads
posix (推荐) or win32
Exception
sjlj (32位) or seh (64位)
配置环境变量解压后,找到bin文件夹,右键复制文件夹路径,如D:\mingw64\bin
打开设置,找到系统-系统信息-高级系统设置并进入:
完成配置后打开cmd,输入gcc -v,出现如下信息时即为成功。
安装扩展在左侧菜单栏选择扩展,搜索c/c++并安装:
配置VSCode的C语言环境按下Ctrl+Shift+P,输入c/c++,选择c/c++:编辑配置(UI):
进入后找到红框对应选项,分别选g++.exe及windows-gcc-x64:
设置完成后,会出现一个c_cpp_p ...

省赛总结·轻舟已过万重山
轻舟已过万重山 20号上午,天气微凉,空气中夹杂着朦胧的小雨。我们踏上了前往珠海参加省赛的路途。六个小时的颠簸车程,令抵达珠海的我头晕不已,到达酒店后倒头就睡。
提交PPT、演练答辩,商讨细节,一晚时间很快便过。
第二天醒来,我看着窗外,迎来了迷人的日出,也迎来了期待已久的省赛。进入会场后,我们马不停蹄地开始取套件、测试硬件、测试作品,商量答辩细节。很快,便轮到了我们。
答辩完成后,我松了一口气,因为展示的过程很顺利,没有出现意外,同时三位评委中两位评委都没有提出问题,而问题也没有太过刁钻,很轻松地回答了过去。既然开了个好头,那接下来的技术测试我便要好好应对了。回到座位上的我心里暗暗想。
时间在不知不觉中慢慢流逝,当来到午餐时间时,我正为解决了识别颜色并框出的题目而暗喜时,传来了不好的消息,貌似模型训练无法正常运转。我开始查看软件报错,都是些从未见过的信息,意识到这条路可能无法走通时,我开始寻找第二种实现方法,最后想到小方舟的自学习分类可以实现这个功能,便让梁嘉欣重新裁剪图片,而我写小方舟的代码,最后小方舟实现了分类功能,时间也刚好耗尽。
盖上电脑,等待评委验收 ...

使用Mx_Yolo_v3训练K210模型文件
一、功能介绍目前提供两种训练:
目标分类: 识别图片所属的种类, 比如图中是苹果还是杯子, 没有坐标。 如下图,识别到了苹果,是苹果的概率为0.8
目标检测: 检测图片中物体的位置, 并且输出这个物体的坐标和物体大小(即框出认识的物体)。 如下图, 识别到了苹果, 并且框出了位置, 是苹果的概率为0.8
二、确定方案
首先确定要训练哪种模型。在上面支持的模型中选择一个,如果不需要检测物体坐标, 用目标分类, 需要坐标则目标识别,两者处理数据要做的工作和格式都不一样, 后者会复杂很多。
确定分类。 包括分类数量, 具体分类。 比如这里以识别红色小球和玩具为例:
所以共两个分类: ball 和 toy, 我们也称之为标签(label),
注意!分类名(标签/label)只能使用英文字符和下划线
确定分辨率。 图片的分辨率也十分重要,不管是在采集、训练,还是使用时, 都需要十分注意, 稍不注意,模型可能就无法使用或者识别精度低。以下为Maixhub目前支持的分辨率,其它分辨率将会训练失败:
目标分类、目标检测: 224x224(推荐)
确定采集数据集(这里就是所有 ...

Python纯代码实现连接SIoT
运行前请确保已安装 paho-mqtt 库,使用命令:pip install paho-mqtt 安装。
1234567891011121314151617181920212223242526272829303132333435363738import paho.mqtt.client as mqtt# 定义SIOT服务器的连接信息broker = "192.168.88.108" # SIoT服务器的地址port = 1883 # SIOT服务器的端口号topic = "ai/G5" # 指定要发布到的主题username = "AIoT"password = "AIoT"# 连接回调函数def on_connect(client, userdata, flags, rc): print("Connected with result code " + str(rc)) # 订阅主题(如果需要) client.subscribe(topic)# 发布消息的回调 ...

论如何将视频导出为图片及批量对文件进行更名
视频导出为图片
打开ScreenToGif,点击最右侧的编辑器:
进入编辑器后,将视频拖进软件界面,点击确定:
静候导入完成后,随机在下方图片中右键,点击浏览文件夹:
获得导出的图片:
批量进行更名
打开拖把更名器:
若提示“注册错误”,无需理会,确定即可进入软件。
在上方菜单栏中点击序号一栏,在模板处输入#,其他配置保持与下图一致,将需要更名的图片全选拖入软件中:
点击图标栏第四个勾号图标,或按下ctrl + e快捷键,即可得到批量更名后的图片,直接覆盖原文件:

OpenCV及k210实现形状检测并计算面积比
Python + OpenCV详细代码12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061626364656667686970717273747576777879808182838485import cv2import numpy as np# 打开摄像头cap = cv2.VideoCapture(0) # cv2.imread("path/to/image.jpg")rectangle_area = 0circle_area = 0line_length = 0while True: # 读取摄像头的帧 ret, frame = cap.read() if not ret: print("Failed to read frame from the camera.") break # 将帧转换为灰度图像 gray ...
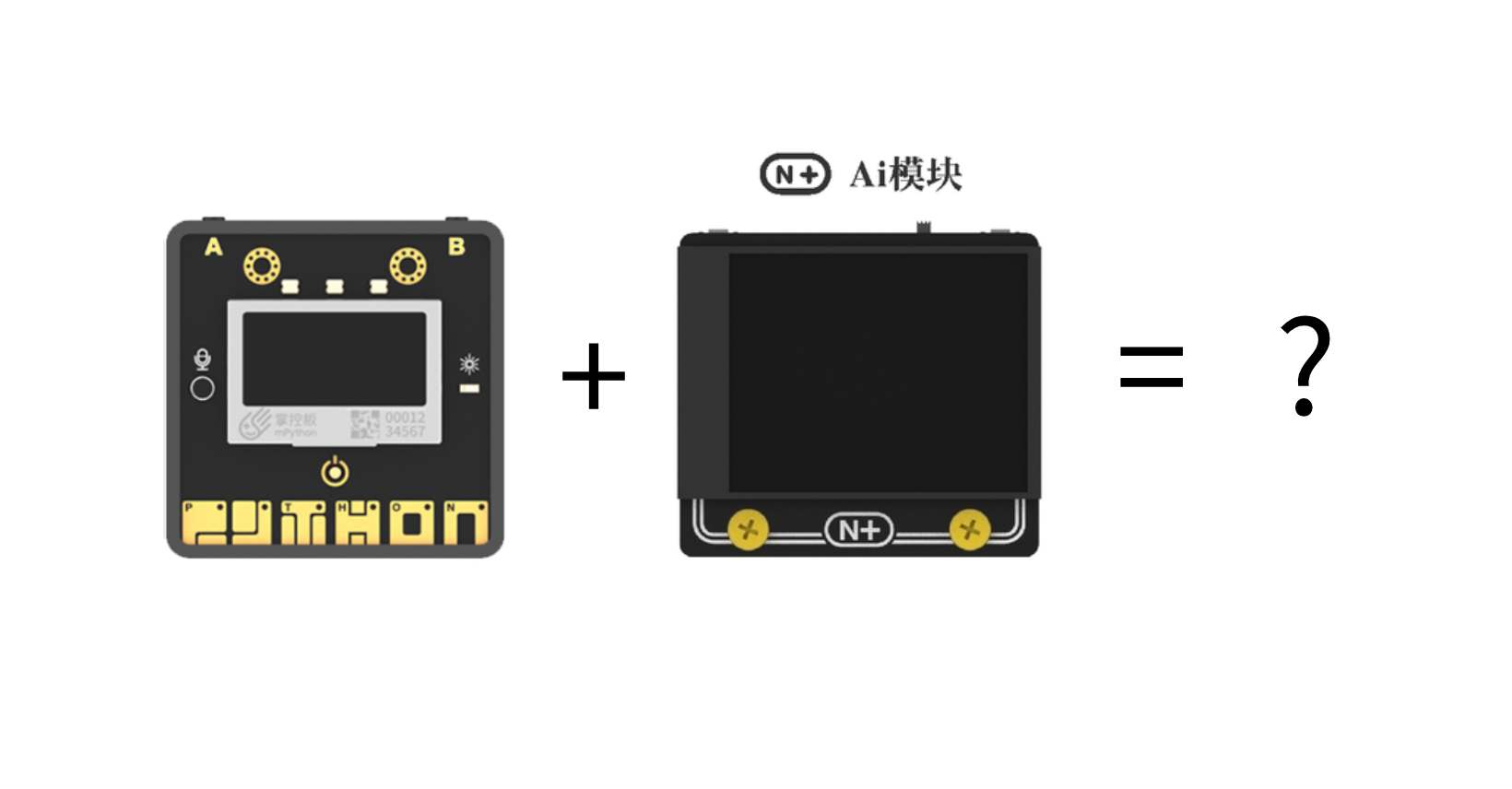
乐动掌控板与小方舟的功能实现
准备工作前往https://www.labplus.cn/software下载mpython软件并安装。
更换主控打开mpython后,点击右上角设置-高级设置-更换主控,选择乐动掌控。
烧录固件乐动掌控将乐动掌控与电脑连接,点击上方未连接,选择对应端口。
点击右上角设置-烧录固件,选择乐动掌控官方固件,确定。
烧录成功后掌控板显示如下图:
小方舟将乐动掌控与电脑连接,点击上方未连接,一般选择端口号较小的端口连接,如若烧录失败再更换。
将小方舟上方的拨片拨至左端!
点击右上角设置-烧录固件,选择AI摄像头2.0固件,确定。
烧录后,若小方舟屏幕显示盛思图标即为成功。
加载扩展库
连接掌控与小方舟
GND与GND相连,VCC同理;
TX与RX反接。
案例人脸识别
编写完成后,点击上方的刷入,完毕后对准人脸按下A键,当学习两个人脸后自动进入识别。
案例2-语音识别.png
中文每个字之间使用-分隔。
待补充……
乐视2高通版x528刷入类原生过程
前言前段时间无聊突然想起床头柜里还有一台小学时社长送的手机,虽然屏幕碎了不少,但是还能用。
让我惊叹的是,16年的机有指纹和人脸识别,支持红外遥控,用起来还算流畅。
不过原来的EUI太过臃肿,自带应用一大堆。贾老板都跑路了还有广告推给你。
于是萌生了给它刷类原生的想法。
注意事项
双清需要清除手机数据!请提前备份!!!
刷机有风险,请小心谨慎!造成的后果请自行承担!!!
本文多图预警,因为多为手机截图,所以用html的语法控制了图片的大小,可能在手机端看起来会有些许小。
所有文件资源都在文末。
解bl锁
去设置里找到开发者选项,打开usb调试和oem解锁。
打不开怎么办
我在打开的时候发现,无论你在开发者选项里做任何操作,退出再进入之后选项都会被还原。在无可奈何的时候想到是不是这个系统的问题,然后果断去恢复出厂设置,竟然还要验证乐视账号。如果你也忘记了的话,那就关机状态下进去官方rec清除吧。(因为这台机子的卡槽不见了,所以开不了usb调试,不过也没关系,可以继续接下来的操作。)
...

Redmi 9利用Magisk实现Root全过程
注意事项
解锁需要清除手机数据!请提前备份!!!
刷机有风险,请小心谨慎!造成的后果请自行承担!!!
本文多图预警,因为多为手机截图,所以用html的语法控制了图片的大小,可能在手机端看起来会有些许小。
所有文件资源都在文末。
本文提供的twrp只支持Redmi 9的Android 10版本!
解bl锁
前往设置-我的设备-全部参数中,连击MIUI版本,直至出现开发者选项已开启等字眼。
前往设置-更多设置-开发者选项中,找到设备解锁状态,点击下方的绑定账号和设备。
前往下载小米官方的解锁工具:工具下载地址
下载得到解锁工具后,打开、登录、清除数据、解锁…
当解锁成功后,再进去开发者选项中即可看到已解锁:
刷入twrp
提前将magisk包放入手机:
打开秋之盒,点击右下角的ADB命令行,选择CMD:
手机在关机状态下按电源键+音量减,进入Bootloader模式:
在cmd中输入以下指令,其中xxx.img为你的twrp文件路径,一般情况下直接将文件拖进黑窗即可得到路径:
1fastboot flash ...

公告
博客更换了新的主题,功能和外观都已趋于完善,开始养老!(bushi)
接下来是住宿的高中生活,只有周日能回家,博客会暂停维护和更新一大段时间。
2023年8月7日

接下来是住宿的高中生活,只有周日能回家,博客会暂停维护和更新一大段时间。
2023年8月7日
